Ultime notizie dal database
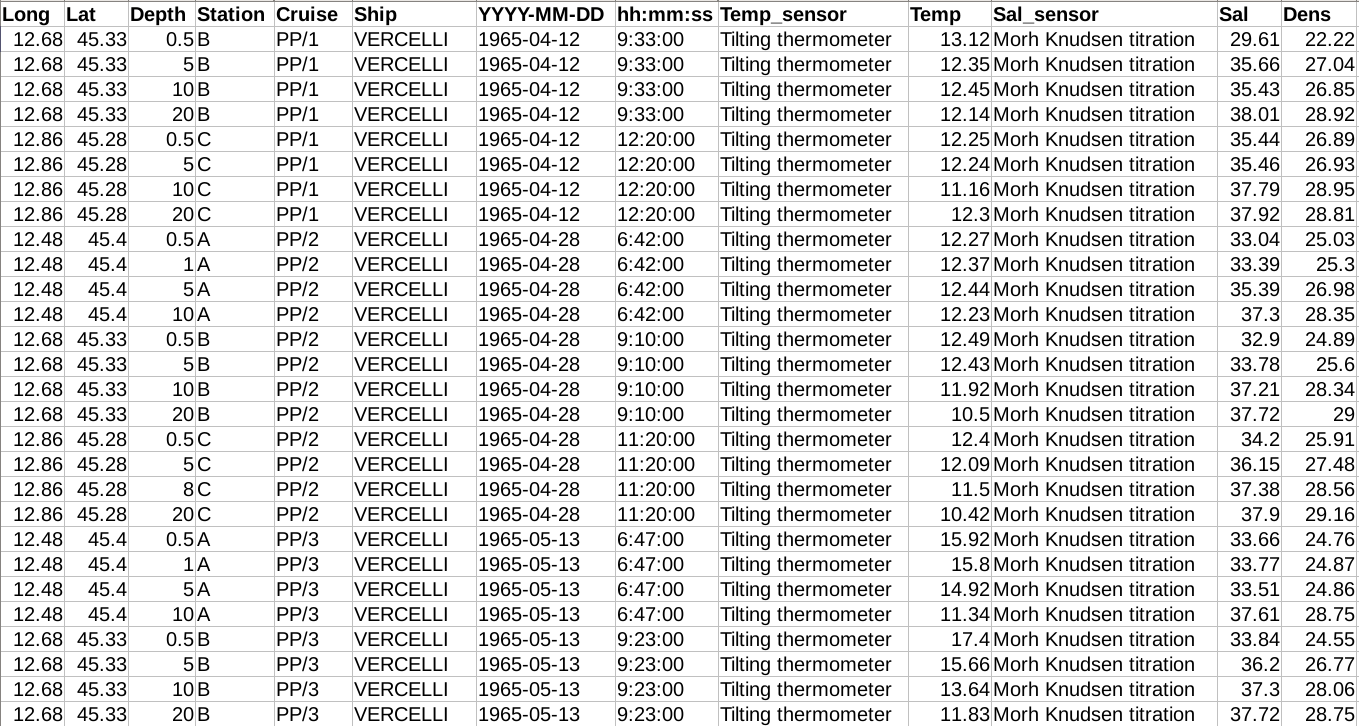
Il nostro database (marino ecologico, a lungo termine) si aggiorna con i dati di zooplancton! Infatti, fino ad ora il database conteneva soli dati abiotici e di fitoplancton - con l’aggiunta di dati di zooplancton finalmente il database può dirsi completo.
Con circa 100000 osservazioni, relative a 21 diversi parametri, il database è stato prima corretto per quanto riguarda i punti ricadenti a terra, quindi armonizzato per quanto riguarda il nome delle stazioni di campionamento utilizzando una routine opportunamente creata e condivisa sul canale Github di CNR-ISMAR come codice Open. La routine sfrutta le potenzialità di GRASS GIS e Python per convogliare i risultati di un’analisi spaziale performante e elevate capacità di text mining in un’unica soluzione. All’interno della cartella del codice sono presenti sia un README (che spiega come istallare ed utilizzare il codice), lo pseudocode in forma grafica, una visualizzazione 3D e una 2D di tutto il database e un brevissimo estratto del database, per finalità di testing del codice.
Contestualmente, sono stati creati i layers vettoriali delle stazioni di campionamento “storiche” (utilizzate fino agli anni 1980) e quello 3D delle osservazioni.
Quindi è stata ricostruita, per ogni parametro, la variazione nei metodi di campionamento ed analisi nel tempo, operazione che ha richiesto sia un lavoro di carattere bibliografico che di esperienza diretta (a seconda dell’anzianità dei dati). In questo modo i metadati sono stati notevolmente arricchiti e si riesce ad ottenere un quadro esauriente della dimensione storica del database.
Attualmente è in corso di redazione un datapaper che sarà pubblicato su Earth System Science Data che riporterà tutti i metadati possibili relativi al database, al meglio delle nostre conoscenze. La rivista Earth System Science data è stata scelta perché garantisce una buona visibilità al lavoro, inoltre richiede che il database sia rilasciato con licenza liberale, che abbia un identificativo univoco (DOI) e che questo sia persistente nel tempo, inoltre da la possiiblità di seguire l’evoluzione nel tempo del database per database dinamici, tramite il processo di “Living Data”. Maggiori aggiornamenti a breve!